From PPO to GDPO — Understanding the Evolution of Reinforcement Learning Algorithms
From PPO to GDPO — Understanding the Evolution of Reinforcement Learning Algorithms
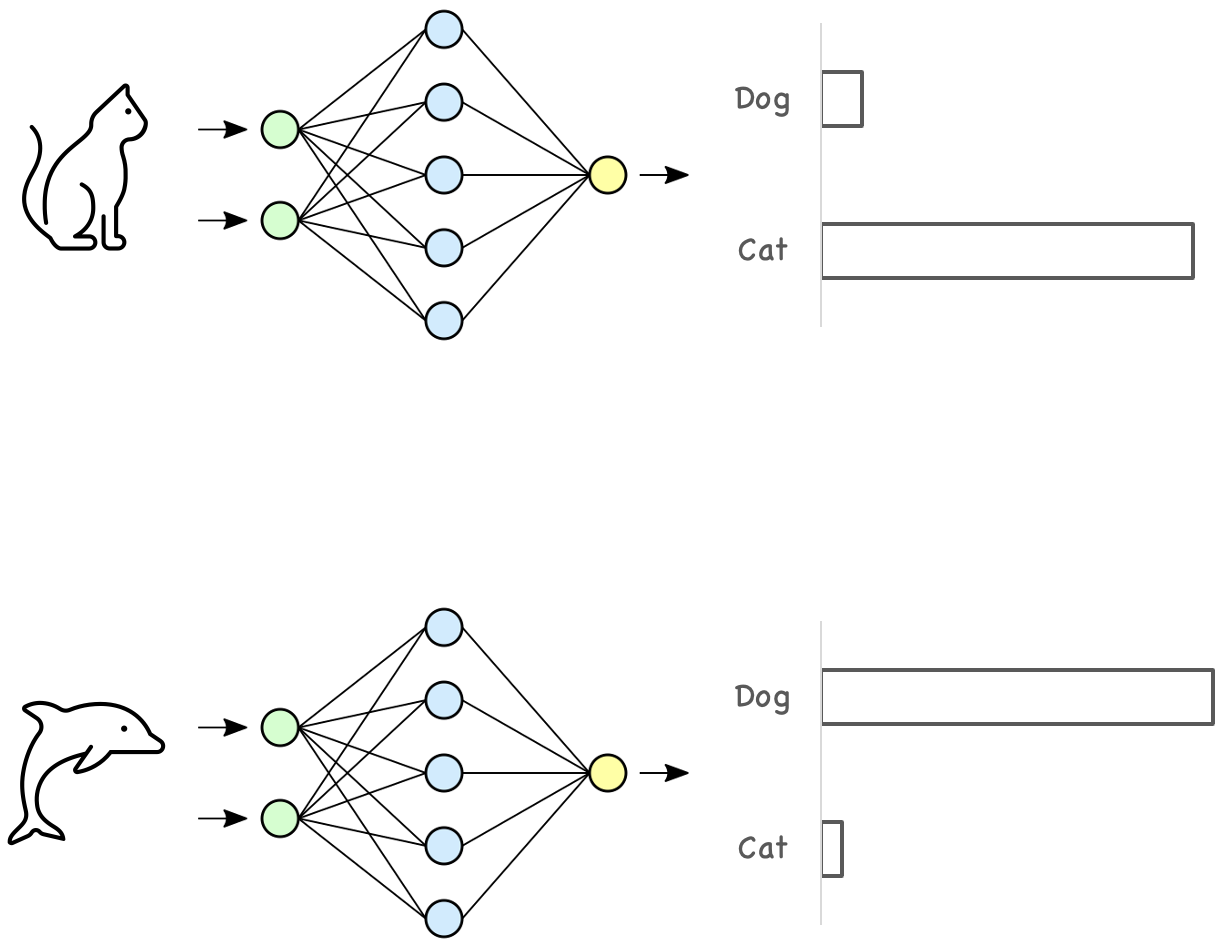
Introduction: Why Reinforcement Learning?
The Two Stages of LLM Training
Training a Large Language Model is fundamentally a two-stage process:
Stage 1: Pre-training (Knowledge Acquisition)
- The model learns from trillions of tokens of text
- It learns to predict the next token: $P(x_t | x_{<t})$
- Result: A “document completor” that understands language structure
Stage 2: Post-training (Behavioral Alignment)
- The model learns to be helpful, harmless, and honest
- It learns to follow instructions and provide useful responses
- Result: A helpful AI assistant
The Problem: A pre-trained model asked “How do I bake a cake?” might respond with “How do I bake a pie?” — continuing a pattern rather than answering the question.