Simple Implementation of Rendezvous Architecture for Machine Learning Services
Stream-First Rendezvous Architecture
The rendezvous architecture was introduced by Ted Dunning in his book Machine Learning Logistics. This architecture is aimed to solve several real-world machine learning challenges:
- To meet large-scale changing data and changing goals.
- Isolation of models for evaluation in specifically customized, controlled environments.
- Managing multiple models in production at any given time.
- Have new models being readied to replace production models as situations change smoothly and without interruptions to service.
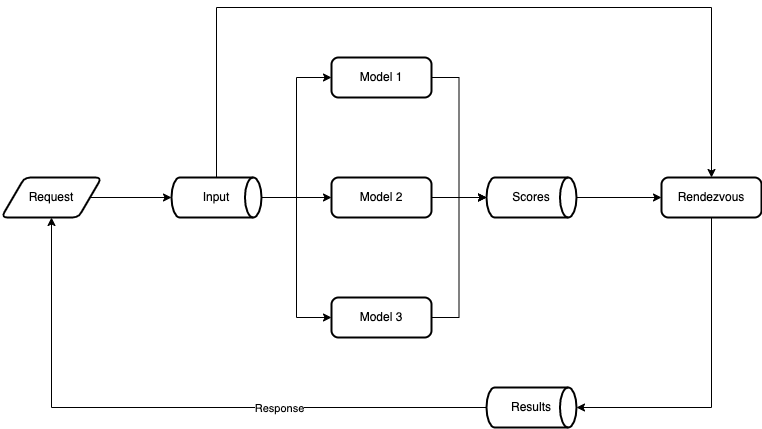
The heart of rendezvous architecture is to treat every input data as stream, i.e.:
- Put all requests into a stream; consumers (models) process input data when needed.
- Outputs of models are put into another stream.
- Rendezvous server works by maintaining a mailbox for each request it sees in the input stream. As each model reports results into the scores stream, the rendezvous server reads these results and inserts them into the corresponding mailbox.
- Based on the amount of time that has passed, the priority of each model and possibly even a random number, the rendezvous server eventually chooses a result for each pending mailbox and packages that result to be sent as a response to the return address in the original request.
If you are interested the details of rendezvous architecture for machine learning, I highly recommend reading the book Machine Learning Logistics and an article Rendezvous Architecture for Data Science in Production written by Jan Teichmann.
Implementation
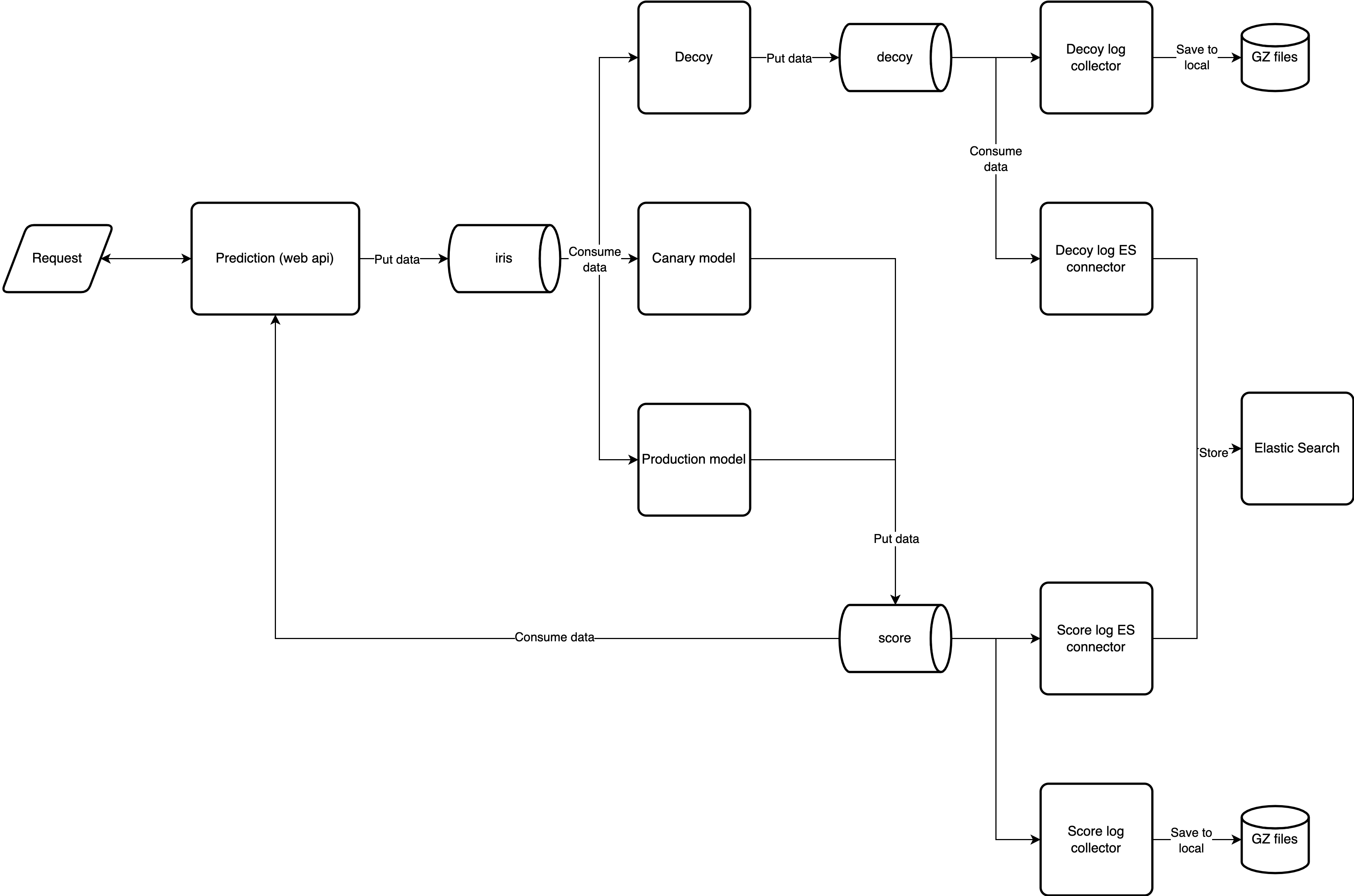
Architecture Diagram
predict The Front End
1 | def predict(flower: Flower): |
Once predict receives a request, it publishes the request body to a topic, i.e., the iris. Then it waits for the result to be published to another topic, score.
1 | def get_model_result(identifier): |
get_model_result gets results from the score topic and will only keep the result from the latest model by comparing the modelVersion. We also impose a time constraint timeout here to ensure our service responds in time.
Prediction Models
1 | while True: |
We have two models, the production model is the latest, and the canary model is the baseline model. We’re trying to recreate the real-world scenario where we have a production model that is actively trained with the latest data, providing better performance. On the other hand, the canary model is usually the first model, intended to be used as a scoring baseline to compare with the production model. By comparing these two models, we can usually detect distribution shifts.
This model predict function will process every data from the iris topic and put model result and relevant debug message into the provenance data field.
Decoy Model
1 | while True: |
The decoy model accepts data like any other model but does not emit any result. Instead, it just archives the inputs that it sees.
Log Connector
1 | while True: |
The log_collector archives every data we received for every timeout second.
ES Connector
1 | while True: |
We also put every result to the elastic search for analytic purposes.
How to Run
Clone my repo here at https://github.com/munhouiani/rendezvous-arch
Install docker and docker compose.
Create conda environment
1
2conda env create -f env_mac.yaml
conda activate rendezvous_archTrain
canaryandproductionmodel1
make train-canary
1
make train-model
Deploy services
1
make up
Wait for several minutes until all services are ready.
Make an HTTP-GET request to
http://localhost:8000/ping, should get1
{"ping": "pong"}
Make an HTTP-POST request to
localhost:8000/predictwith body:1
2
3
4
5
6{
"sepalLength": 9,
"sepalWidth": 10,
"petalLength": 11,
"petalWidth": 12
}should get
1
2
3
4
5
6
7
8
9
10
11
12
13
14{
"timestamp": 1644370787.021771,
"messageId": "cec42337-49ad-4f19-a478-69a1ef480e8a",
"modelInput": {
"sepalLength": 9.0,
"sepalWidth": 10.0,
"petalLength": 11.0,
"petalWidth": 12.0
},
"modelResult": {
"modelName": "dt",
"result": 2
}
}Create indices for
decoy-logandscore-logat Kibanahttp://localhost:5601.