Pytorch Implementation of Deep Packet: A Novel Approach For Encrypted Traffic Classification Using Deep Learning
Why Traffic Classification
The authors explained that network traffic classification attracts many interests in both academia and industrial area is because it is one of the prerequisites for advanced network management task. Network architecture today is designed to be asymmetric, based on the assumption that clients demand download more than upload. However, this assumption doesn’t hold anymore due to the rise of voice over IP (VoIP), P2P, and other symmetric-demand application. Network providers require the knowledge of the application their clients used to allocate adequate resources.
Related Works
The authors categorised network classification methods into three categories: (1) port-based (2) payload inspection, and (3) statistical machine learning. The summary of the pros and cons of these methods are as below:
Port-based: classifies traffic by the port number in TCP/UDP header
- Pros: Fast
- Cons: Inaccurate, due to port obfuscation, network address translation (NAT), port forwarding, protocol embedding, and random ports assignment
Payload inspection: analyse the payload in the application layer
- Pros: Accurate
- Cons: Pattern-based. Needs to update patterns each time a new protocol is released. Another issue is that this method raises user privacy concern.
Statistical and machine learning: use statistical features of traffic to train a model
- Pros: Accurate
- Cons: Expensive and inefficient as it needs human involved hand-craft features. Slow execution of machine learning model is another concern.
Dataset
They used the VPN-nonVPN dataset (ISCXVPN2016). This dataset was captured at the data-link layer. Hence each packet contains an Ethernet header, an IP header, and a TCP/UDP header.
Pre-processing
During the pre-processing phase, the authors
- Remove Ethernet header
- Pad traffic with UDP header with zeros to the length of 20 bytes
- Mask the IP in the IP header
- Remove irrelevant packets such as packets with no payload or DNS packets
- Convert the raw packet into a bytes vector
- Truncate the vector of size more than 1500, pad zeros for the byte vector less than 1500
- Normalise the bytes vector by dividing each element by 255
I used Scapy to modify the packets.
1 | def remove_ether_header(packet): |
Deep Packet
The authors proposed two models. One is CNN, and another is SAE. I only implemented the CNN model, so I introduce only their CNN architecture here.
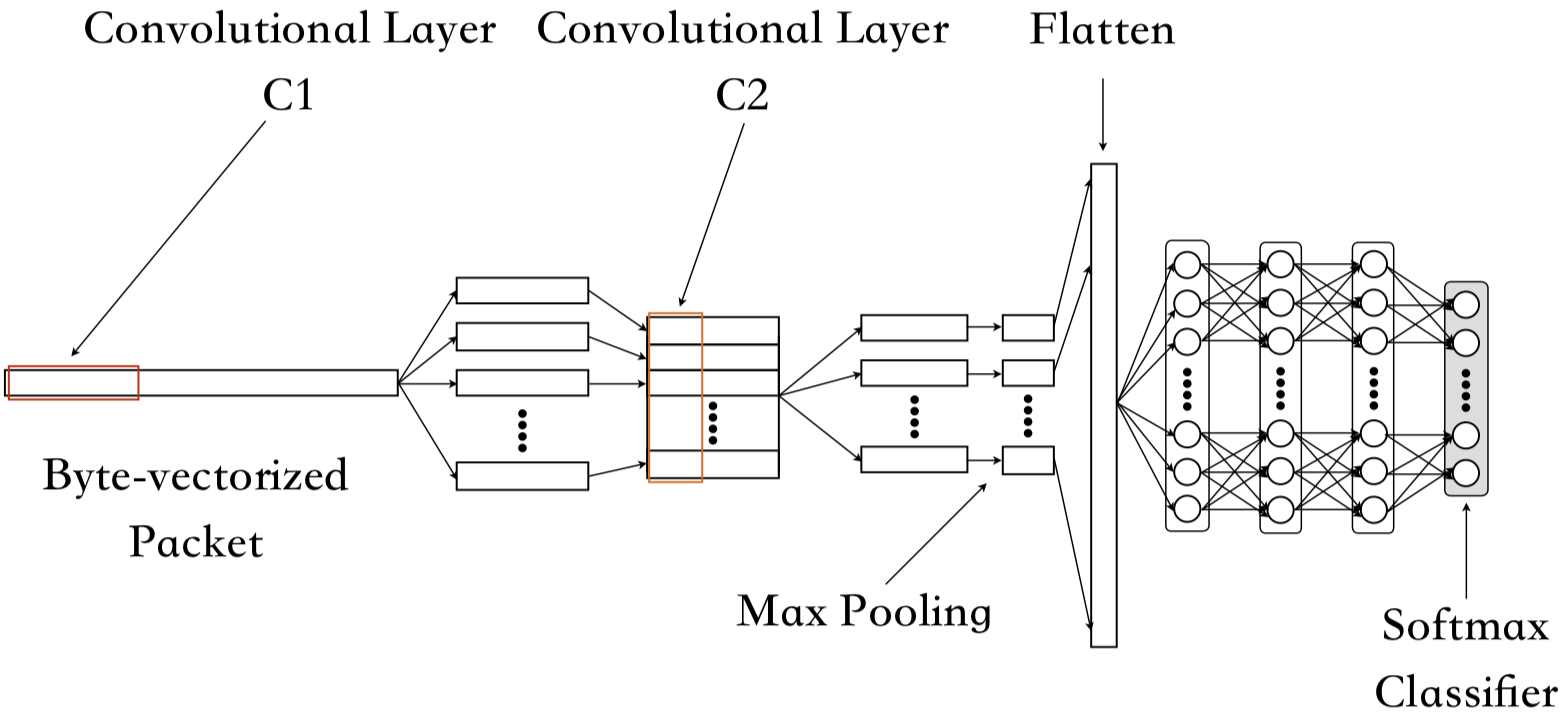
The input of their CNN model is a vector of size 1,500. It consists of two consecutive 1-D convolutional layers, followed by a max-pooling layer. Afterwards, the tensor will be flattened and fed into 4 fully connected layers, while the last layer acts as the softmax classifier. The revealed hyperparameters of their convolutional layers, which are

However, they didn’t mention the kernel size of the max-pooling layer and the sizes of three dense layers. I set the kernel size to 2, while for the dense layers, I use the setting of the last three layers of their SAE model, which are 200, 100, and 50.
1 | class CNN(LightningModule): |
Create Train and Test Data
For each of the application and traffic classification tasks, the dataset is first stratified split into train set and test set with the ratio of 80:20, then each class in the train set are rebalanced by under-sampling. I used all data in the application classification task, but for the traffic classification task, I used only certain apps traffic in each traffic category. This is because I do not know the traffic category of certain apps which are not mentioned in the dataset description page. The applications I used for the traffic classification task are as follow:
| Traffic Category | Applications |
|---|---|
| SMPTS, POP3S and IMAPS | |
| Chat | ICQ, AIM, Skype, Facebook and Hangouts |
| Streaming | Vimeo and Youtube |
| File Transfer | Skype, FTPS and SFTP |
| VoIP | Facebook, Skype and Hangouts voice calls |
| Torrent | uTorrent and Transmission (Bittorrent) |
Evaluation Result
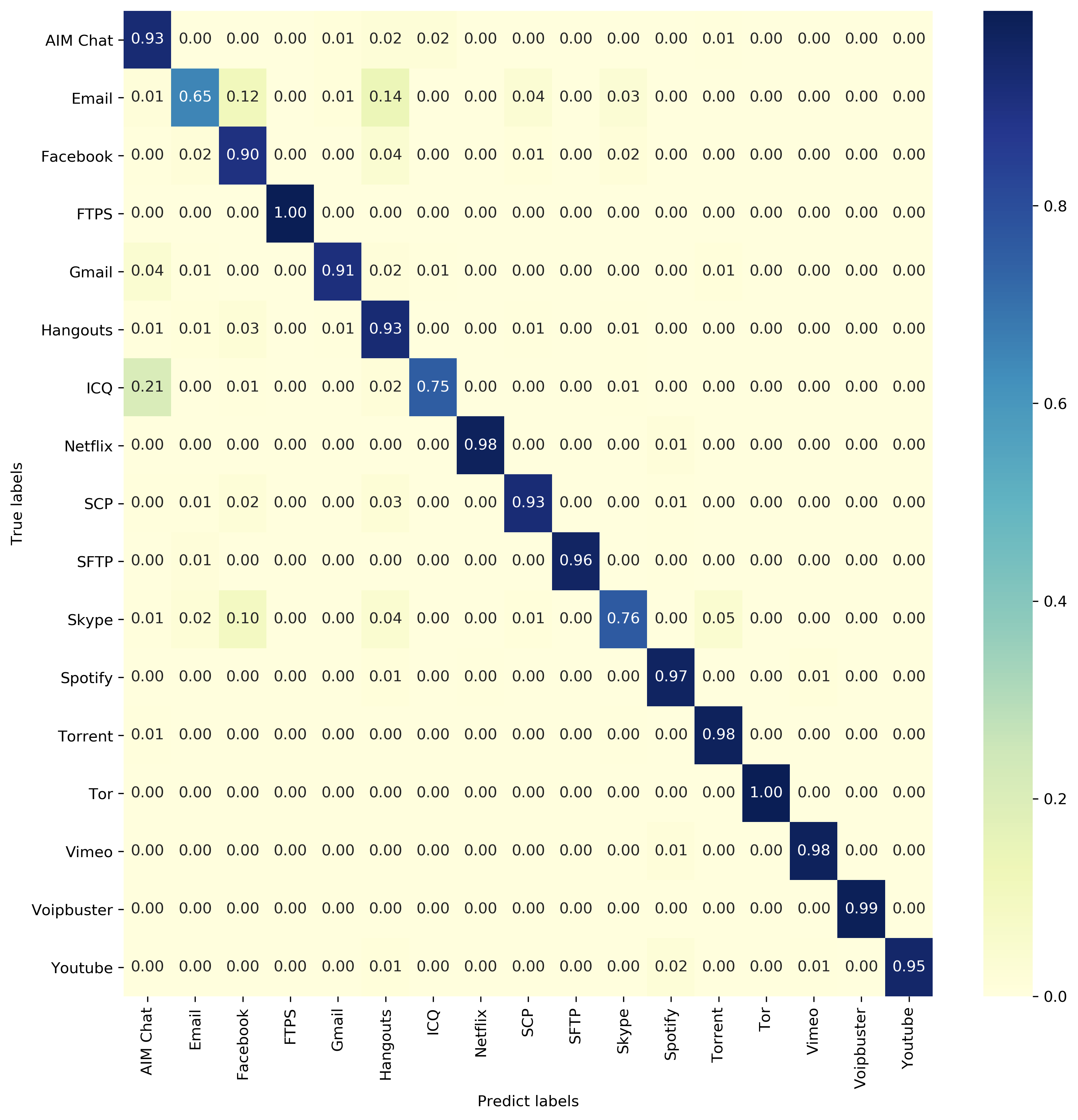
Application classification
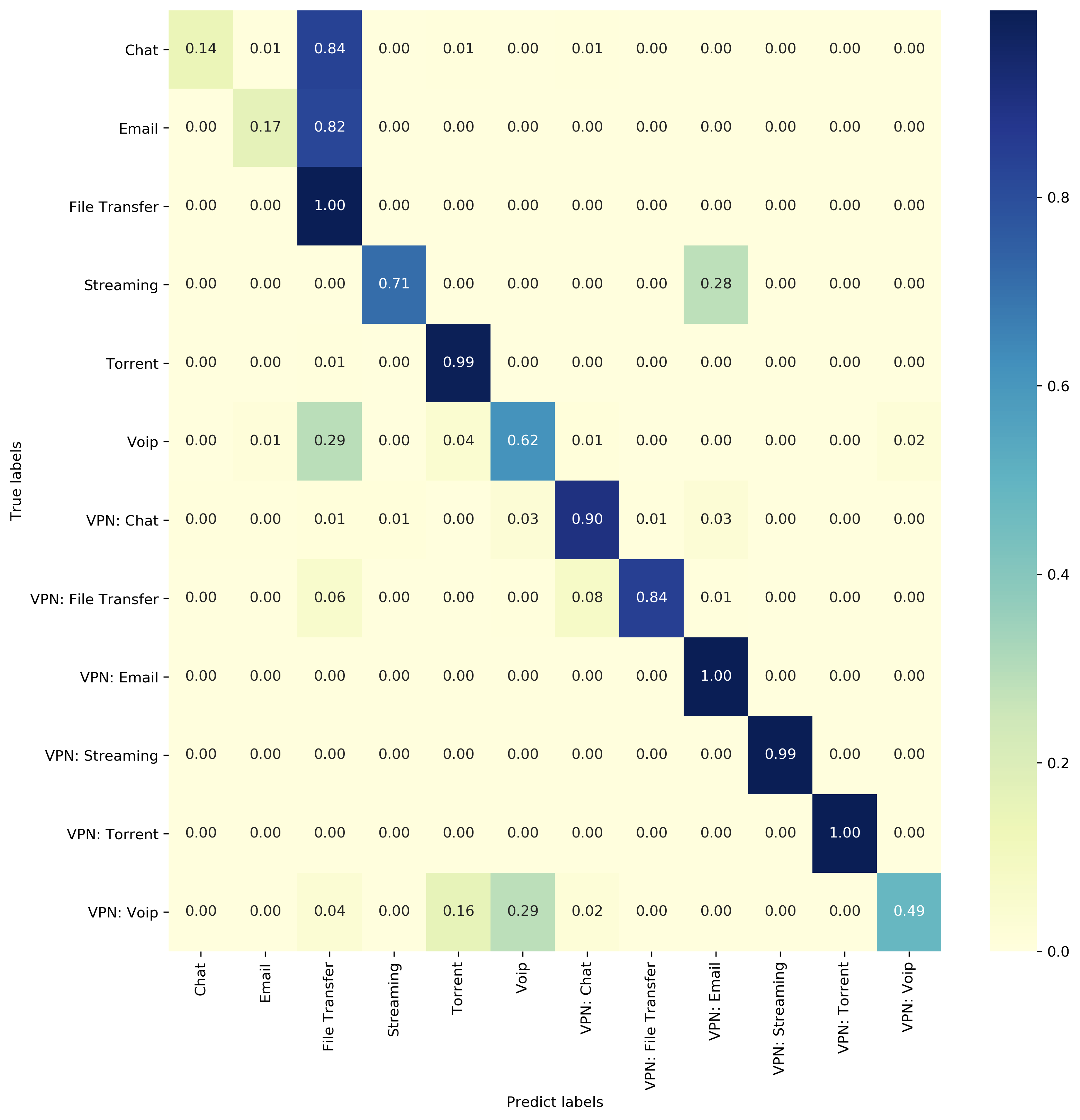
Traffic classification
The model performance is closed but not as good as they claimed. This is probably due to the difference between the composition of the train set and the hyperparameter settings.
Data Model and Code
You can download the train and test set I created at here and clone the code from Github.
Pre-trained models are available at here.